

This is the first of two case studies that I have involving Google News and AMP for different news publishers. If you are looking for a Google News and AMP specialist then contact me for a consultation call.
In 2020 I helped a US entertainment news publisher increase Google News traffic to a whole section of their site by 98% in a month.

Fixing AMP & Meta Robots Nofollow Bug
This traffic increase was due to fixing a technical SEO problem, then implementing a news optimisation strategy.
I looked at historical data and determined that for some reason this section of the site was not appearing in Google News results such as Top Stories or Google’s Discover feed.
Tools like Ahrefs and Search Console were not giving me any indication as to why these pages weren’t showing up so I used Screaming Frog to crawl the site.
This revealed to me that there were certain limitations on crawling taking place, and that this was because of a tag called robots-meta. This tag was set to “nofollow”, which tells Google not to follow any links on a page. That includes links to images and external resources such as AMP. So it wasn’t that Google News wasn’t indexing the pages or something to do with content quality or Google News guidelines, it was that Google could not see the required images and some of the structured data (in this case provided by AMP) that is needed for Google News.
Optimising for Google News
Once the technical issue was fixed pages began appearing in Google News again. The next step was to optimize for news and discover results. This is not the same strategy as with typical SEO. For example, Google News and Google’s Discover service rely more heavily on entity recognition to serve results.
One way to optimize for both News and Discover is to find the entities that have high search volume and that have news carousel result. For example, brands, celebrities, & news events. You can find these by looking at Search Console data and looking at traffic spikes. This is similar to keyword research in some ways but also very different.
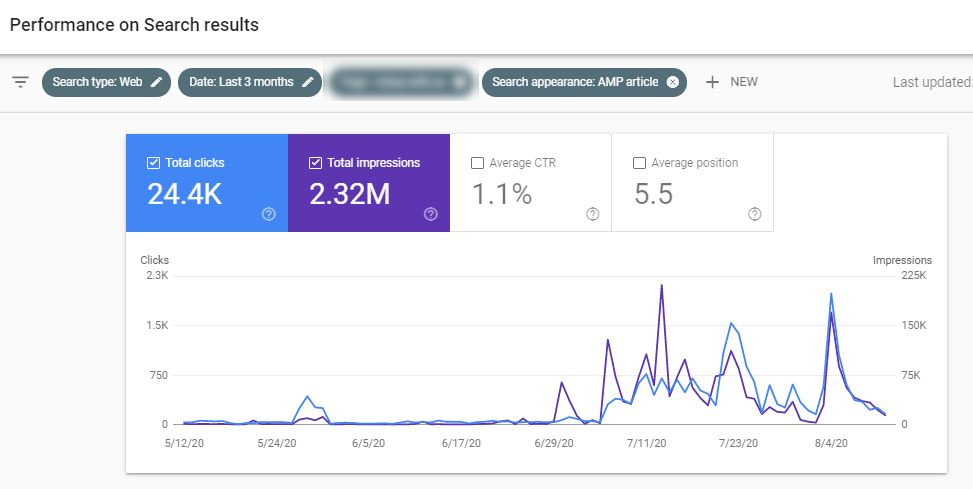
In this case we used brands and celebrity names within titles that had been shown to work in the past. In Google News this means the articles appear in Top Stories for searches for the celebrity, while in Discover users who have previously read about that celebrity or brand are also shown news relating to that person or brand entity.
These spikes in traffic led to a 98% increase in overall traffic to this section of the website.
Takeaways
Google Discover is (in part) powered by entity recognition and organising information around entities, whereby users are served news that they may be interested in based on previous search and browsing behaviour that was connected to a specific entity. This is probably powered by Google’s Knowledge Graph.
For example, if you read entertainment news stories about Jennifer Lopez, Google will think you are interested in this person and they will resurface in your feed if news articles are published about them. Other entities can be topics, keywords, places, and so on.
It will be interesting to see how publishers and news SEOs try to optimize for this.
Recommendations for Google News publishers
My recommendation is to start by analyzing spikes in traffic from Discover and to put together a list of entities and keywords to use in article headings. Some of these will be evergreen with reliable traffic, while others will be one off spikes so check them in Google Trends. Then create a Google News checklist for writers and editors that reminds them to use entity terms where appropriate in article titles (also remember Google News doesn’t use meta titles – it uses the page title). This can be an effective strategy for smaller news publishers too. In many cases it will be something that happens naturally but it is worth knowing how it works and how to optimize for it too.
